

Роль и характеристики кэш-памяти L2 и L3: особенности и преимущества
Характеристики кэш-памяти L2 и L3:
Объем: Кэш-память L2 имеет больше объема, чем L1, и обычно составляет несколько мегабайт. Кэш-память L3 может быть еще большего объема и измеряется в нескольких мегабайтах или даже гигабайтах. Больший объем кэш-памяти позволяет хранить больше данных, что увеличивает вероятность кэширования нужных данных и улучшает производительность системы.
Скорость доступа: Кэш-память L2 и L3 имеет большее время доступа, чем L1, но все равно гораздо быстрее, чем оперативная память. Обычно время доступа к кэш-памяти L2 составляет несколько наносекунд, а кэш-памяти L3 — несколько десятков наносекунд. Быстрый доступ к данным в кэш-памяти L2 и L3 позволяет ускорить обработку команд и улучшить производительность процессора.
Уровень в иерархии: Кэш-память L2 и L3 находятся на более высоких уровнях иерархии кэш-памяти, чем L1. Это означает, что данные сначала попадают в L1 кэш-память, а затем, если их там нет, происходит обращение к L2 и L3. Более высокий уровень кэш-памяти обычно связан с более медленным доступом, но большим объемом памяти.
Преимущества кэш-памяти L2 и L3:
Увеличение объема памяти: Кэш-память L2 и L3 увеличивает доступное пространство для хранения данных, что позволяет улучшить вероятность кэширования и снизить время доступа к данным.
Улучшение производительности: Доступ к данным в кэш-памяти L2 и L3 происходит быстрее, чем доступ к оперативной памяти. Благодаря этому, кэш-память L2 и L3 помогает ускорить выполнение команд и повысить производительность системы в целом.
Оптимизация загрузки: Кэш-память L2 и L3 могут хранить данные, которые будут использоваться в ближайшем будущем. Это позволяет заранее загружать данные из оперативной памяти в кэш-память, что снижает время ожидания и улучшает производительность системы.
Гибкость конфигурации: Кэш-память L2 и L3 имеет настройки, которые можно изменять в зависимости от потребностей системы. Это позволяет оптимизировать кэш-память под конкретные задачи и увеличить производительность системы.
Кэш-хит или мисс и латентность
Данные поступают из ОЗУ в кэш L3, затем в L2 и, наконец, в L1. Когда процессор ищет данные для выполнения операции, он сначала пытается найти их в кэше L1. Если процессор может его найти, условие называется попаданием в кэш. Затем он находит его в L2, а затем в L3.
Если он не находит данные, он пытается получить к ним доступ из основной памяти. Это называется пропуском кеша.
Теперь, как мы знаем, кэш предназначен для ускорения передачи информации между основной памятью и процессором. Время, необходимое для доступа к данным из памяти, называется задержкой. L1 имеет самую низкую задержку, будучи самой быстрой и ближайшей к ядру, а L3 имеет самую высокую. Задержка увеличивается очень много, когда происходит потеря кэша. Это потому, что процессор должен получать данные из основной памяти.
По мере того, как компьютеры становятся быстрее и лучше, мы наблюдаем снижение задержки. Теперь у нас есть оперативная память DDR4 с низкой задержкой и сверхбыстрые твердотельные накопители с низким временем доступа в качестве основного хранилища, которые значительно сокращают общую задержку. Если вы хотите узнать больше о том, как работает ОЗУ, вот наше краткое и грязное руководство по оперативной памяти
Ранее в конструкциях кешей использовались кэши L2 и L3 вне ЦП, что отрицательно сказывалось на задержке.
Однако прогресс в процессах изготовления, связанных с транзисторами процессора, позволил разместить миллиарды транзисторов в меньшем пространстве, чем раньше. В результате для кеша остается больше места, что позволяет кешу быть как можно ближе к ядру, значительно сокращая время ожидания.
Первые шаги к созданию универсальных процессоров
История создания центральных процессоров насчитывает множество вех, но первые шаги в направлении создания универсальных процессоров были сделаны в середине XX века.
Одним из ранних прорывов в этой области стало создание серии компьютеров UNIVAC в 1950-х годах. Эти компьютеры, разработанные для военных и коммерческих целей, были оснащены первыми универсальными процессорами, которые могли выполнять разнообразные задачи с помощью программного обеспечения.
Продвижение в создании универсальных процессоров также было обусловлено развитием технологий интегральных схем, которые позволяли упаковывать большое количество транзисторов на одну микрочиповую плату. Это позволило увеличить вычислительные мощности и функциональные возможности процессоров.
На заре эры универсальных процессоров разработчики сталкивались с множеством технических и архитектурных проблем. Вопросы связанные с архитектурой процессоров, их эффективностью и совместимостью с программным обеспечением были основными проблемами, которые требовало решить на пути к созданию универсальных процессоров.
Тем не менее, благодаря упорному труду и научным исследованиям, компьютерные специалисты смогли постепенно устранить проблемы и разработать первые полноценные универсальные процессоры, открывая новые горизонты для развития компьютерных технологий и информационной революции.
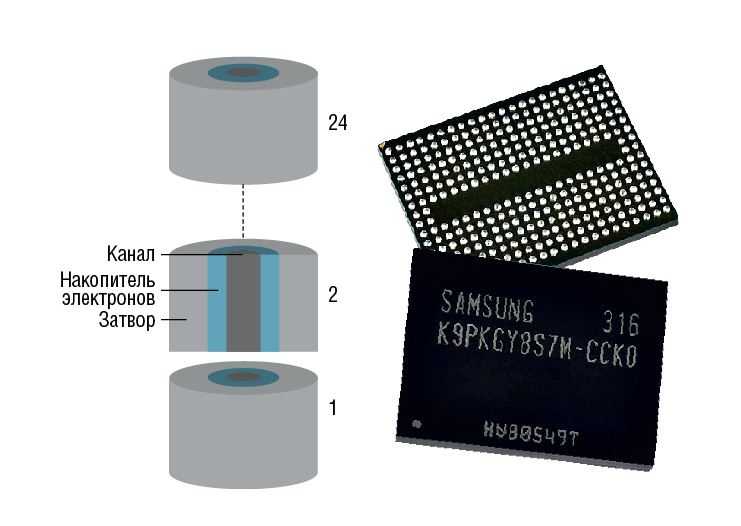
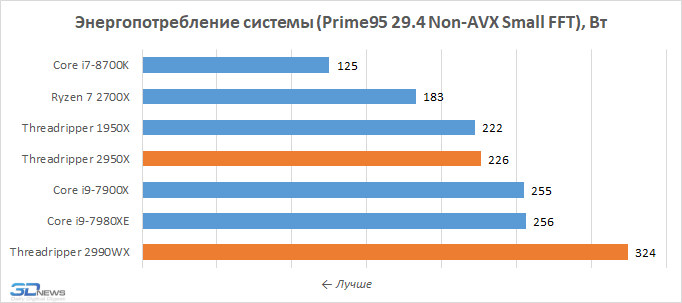
Конфигурация условной 36 ядерной машины
-
Процессоры
. 36 ядер, x86-64 ISA, 2.4 GHz, Silvermont-like OOO: 8B-wide
ifetch; 2-level bpred with 512×10-bit BHSRs + 1024×2-bit PHT, 2-way decode/issue/rename/commit, 32-entry IQ and ROB, 10-entry LQ, 16-entry SQ; 371 pJ/instruction, 163 mW/core static power -
Кэши уровня L1
. 32 KB, 8-way set-associative, split data and instruction caches,
3-cycle latency; 15/33 pJ per hit/miss -
Служба предварительной выборки Prefetchers
. 16-entry stream prefetchers modeled after and validated against
Nehalem -
Кэши уровня L2
. 128 KB private per-core, 8-way set-associative, inclusive, 6-cycle latency; 46/93 pJ per hit/miss -
Когерентный режим (Coherence)
. 16-way, 6-cycle latency directory banks for Jenga; in-cache L3 directories for others -
Global NoC
. 6×6 mesh, 128-bit flits and links, X-Y routing, 2-cycle pipelined routers, 1-cycle links; 63/71 pJ per router/link flit traversal, 12/4mW router/link static power -
Блоки статической памяти SRAM
. 18 MB, one 512 KB bank per tile, 4-way 52-candidate zcache, 9-cycle bank latency, Vantage partitioning; 240/500 pJ per hit/miss, 28 mW/bank static power -
Многослойная динамическая память Stacked DRAM
. 1152MB, one 128MB vault per 4 tiles, Alloy with MAP-I DDR3-3200 (1600MHz), 128-bit bus, 16 ranks, 8 banks/rank, 2 KB row buffer; 4.4/6.2 nJ per hit/miss, 88 mW/vault static power -
Основная память
. 4 DDR3-1600 channels, 64-bit bus, 2 ranks/channel, 8 banks/rank, 8 KB row buffer; 20 nJ/access, 4W static power -
DRAM timings
. tCAS=8, tRCD=8, tRTP=4, tRAS=24, tRP=8, tRRD=4, tWTR=4, tWR=8, tFAW=18 (все тайминги в tCK; stacked DRAM has half the tCK as main memory)
Всем пользователям хорошо известны такие элементы компьютера, как процессор, отвечающий за обработку данных, а также оперативная память (ОЗУ или RAM), отвечающая за их хранение. Но далеко не все, наверное, знают, что существует и кэш-память процессора(Cache CPU), то есть оперативная память самого процессора (так называемая сверхоперативная память).
В чем же состоит причина, которая побудила разработчиков компьютеров использовать специальную память для процессора? Разве возможностей ОЗУ для компьютера недостаточно?
Действительно, долгое время персональные компьютеры обходились без какой-либо кэш-памяти. Но, как известно, процессор – это самое быстродействующее устройство персонального компьютера и его скорость росла с каждым новым поколением CPU. В настоящее время его скорость измеряется миллиардами операций в секунду. В то же время стандартная оперативная память не столь значительно увеличила свое быстродействие за время своей эволюции.
Вообще говоря, существуют две основные технологии микросхем памяти – статическая память и динамическая память. Не углубляясь в подробности их устройства, скажем лишь, что статическая память, в отличие от динамической, не требует регенерации; кроме того, в статической памяти для одного бита информации используется 4-8 транзисторов, в то время как в динамической – 1-2 транзистора. Соответственно динамическая память гораздо дешевле статической, но в то же время и намного медленнее. В настоящее время микросхемы ОЗУ изготавливаются на основе динамической памяти.
Примерная эволюция соотношения скорости работы процессоров и ОЗУ:
Таким образом, если бы процессор брал все время информацию из оперативной памяти, то ему пришлось бы ждать медлительную динамическую память, и он все время бы простаивал. В том же случае, если бы в качестве ОЗУ использовалась статическая память, то стоимость компьютера возросла бы в несколько раз.
Именно поэтому был разработан разумный компромисс. Основная часть ОЗУ так и осталась динамической, в то время как у процессора появилась своя быстрая кэш-память, основанная на микросхемах статической памяти. Ее объем сравнительно невелик – например, объем кэш-памяти второго уровня составляет всего несколько мегабайт. Впрочем, тут стоить вспомнить о том, что вся оперативная память первых компьютеров IBM PC составляла меньше 1 МБ.
Кроме того, на целесообразность внедрения технологии кэширования влияет еще и тот фактор, что разные приложения, находящиеся в оперативной памяти, по-разному нагружают процессор, и, как следствие, существует немало данных, требующих приоритетной обработки по сравнению с остальными.
Что такое техпроцесс в процессоре: важность размер кристалла
Доброго времени суток.
Давайте вместе приоткроем завесу такого сложного дела как производство CPU для компьютеров. В частности, из этой статьи вы узнаете, что такое техпроцесс в процессоре и почему с каждым годом разработчики стараются его уменьшить.
Как изготавливаются процессоры?
Для начала вам стоит знать ответ на данный вопрос, чтобы дальнейшие разъяснения были понятны. Любая электронная техника, в том числе и CPU, создается на основе одного из наиболее часто используемых минералов — кристаллов кремния. Причем применяется он в данных целях уже более 50 лет.
Кристаллы обрабатываются посредством литографии для возможности создания отдельных транзисторов. Последние являются основополагающими элементами чипа, так как он полностью состоит из них.

Функция транзисторов заключается в блокировке или пропуске тока, в зависимости от актуального состояния электрического поля. Таким образом, логические схемы работают по двоичной системе, то есть в двух положениях — включения и выключения. Это значит, что они либо пропускают энергию (логическая единица), либо выступают в роли изоляторов (ноль). При переключении транзисторов в CPU производятся вычисления.




Теперь о главном
Если говорить обобщенно, то под технологическим процессом понимается размер транзисторов.
Что это значит? Снова вернемся к производству процессоров.
Чаще всего применяется метод фотолитографии: кристалл покрыт диэлектрической пленкой, и из него вытравливаются транзисторы с помощью света. Для этого используется оптическое оборудование, разрешающая способность которого, по сути, и является техническим процессом. От ее значения — от точности и чувствительности аппарата — зависит тонкость транзисторов на кристалле.

Что это дает?
Как вы понимаете, чем они будут меньше, тем больше их можно расположить на чипе. Это влияет на:
- Тепловыделение и энергопотребление. Из-за уменьшения размера элемента он нуждается в меньшем количестве энергии, следовательно, и меньше выделяет тепла. Данное преимущество позволяет устанавливать мощные CPU в небольшие мобильные устройства. Кстати, благодаря низкому энергопотреблению современных чипов, планшеты и смартфоны дольше держат заряд. Что касается ПК, пониженное тепловыделение дает возможность упростить систему охлаждения.
- Численность заготовок. С одной стороны, производителям выгодно уменьшать техпроцесс, потому что из одной заготовки получается большее количество продукции. Правда, это лишь следствие утончения техпроцесса, а не преследование выгоды, потому что с другой стороны, чтобы снизить размер транзисторов, необходимо более дорогое оборудование.

Техпроцесс в числах и примерах
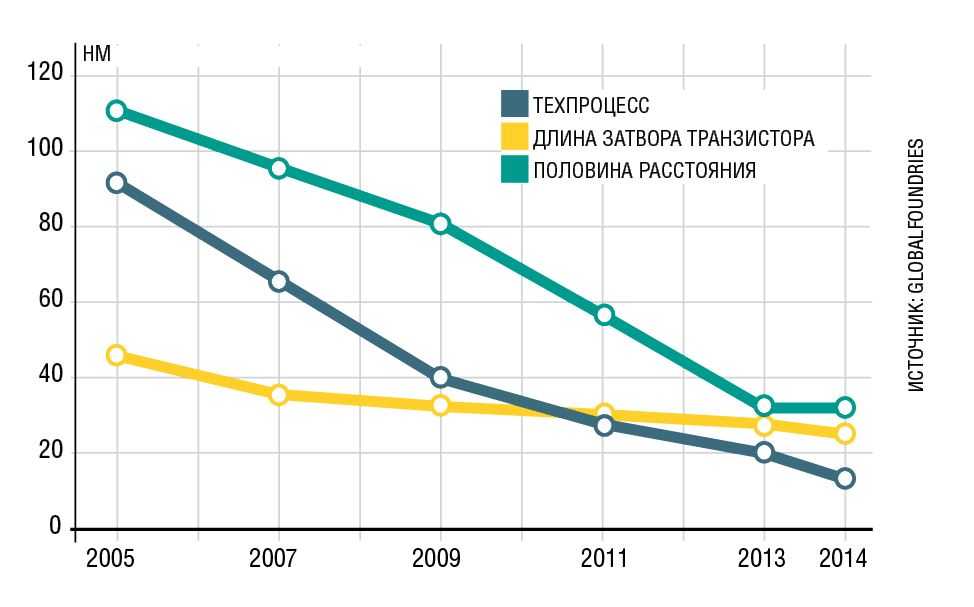
Измеряется технологический процесс в нанометрах (нм). Это 10 в -9 степени метра, то есть один нанометр является миллиардной его частью. В среднем, современные процессоры производятся по техпроцессу 22 нм.
Можете себе представить, сколько транзисторов умещается на процессоре. Чтобы вам было понятнее, на площади среза человеческого волоса могут разместиться 2000 элементов. Хоть чип и миниатюрный, но явно больше волоска, поэтому может включать в себя миллиарды транзисторных затворов.
Хотите знать точнее? Приведу несколько примеров:
В процессорах фирмы AMD, а именно Trinity, Llano, Bulldozer, техпроцесс составляет 32 нм. В частности, площадь кристалла последнего — 315 мм2, где располагаются 1,2 млрд. транзисторов. Phenom и Athlon того же производителя выполнены по техпроцессу 45 нм, то есть имеют 904 млн. при площади основания 346 мм2.


К слову, все, что вы узнали о техпроцессах для центральных компьютерных аппаратов, применимо и к графическим устройствам. Например, данное значение в видеокартах AMD (ATI) и Nvidia составляет 28 нм.

Теперь вы знаете больше о таком важном компоненте вашего компьютера как процессор. Возвращайтесь за новой информацией
До скорого.
Эффективность GPU: TDP vs площадь кристалла
Если не учитывать техпроцесс, и вместо количества транзисторов на кристалле использовать в анализе лишь площадь кристалла, то мы увидим совершенно иную картину…
На этом графике эффективность увеличивается так же, но теперь мы видим, что некоторые ключевые позиции поменялись местами. TU102 и GV100 «осыпались», тогда как Navi 10 и Vega 20 подпрыгнули. Это связано с тем, что первые два процессора представляют собой огромные чипы (754 мм2 и 815 мм2), тогда как последние два от AMD намного меньше (251 мм2 и 331 мм2).
Оставим на графике только самые последние разработки, чтобы подчеркнуть различия:
Становится очевидным, что AMD пренебрегает энергоэффективностью в пользу уменьшения размеров кристалла.
Другими словами, AMD хотят получить больше GPU чипов с каждой произведённой кремниевой пластины, в то время как Nvidia, похоже, придерживается стратегии увеличения энергоэффективности каждого чипа в ущерб его размеру и, соответственно, стоимости изготовления (чем больше чип, тем меньше их можно разместить на одной пластине).
Продолжат ли AMD и Nvidia впредь следовать выбранным стратегиям? Первые уже заявили, что в RDNA 2.0 они намерены на 50% улучшить соотношение «производительность на ватт», поэтому мы ждём их новые GPU дальше справа, по нашему графику. А что насчет Nvidia?
А они, к сожалению, печально известны своей молчаливостью относительно своих планов. Но известно, что их новые процессоры будут производить TSMC и Samsung на том же техпроцессе, который использовался для Navi. Были некоторые заявления о том, что мы увидим значительное снижение энергопотребления, и в то же время большое увеличение количества унифицированных шейдеров. Поэтому, судя по всему, Nvidia также не нарушит тенденций на нашем графике.
Больше, чем просто число
Кэш повышает производительность, ускоряет передачу данных логическим блокам и удерживает поблизости копии часто используемых данных и инструкций. Хранящаяся в кэше информация разделена на две части: сами данные и адрес, откуда они взяты в памяти или накопителе. Этот адрес называется тег кэша.
Когда процессор выполняет операцию, где нужно записывать или считывать данные в память или из памяти, он начинает проверять теги в кэше первого уровня. Если тег найден (cache hit, попадание в кэш, удачное обращение к кэш-памяти), доступ к данным осуществляется почти сразу. Промах кэша (cache miss) происходит, когда тег не найден в кэше нижнего уровня.
В результате происходит почти непрерывное перемещение данных, на которое уходит всего несколько тактов процессора. Для достижения этого нужна сложная структура вокруг SRAM, которая управляет данными. Если бы процессор состоял всего из одного АЛУ, кэш L1 был бы намного проще.
В реальности их десятки, многие способны обрабатывать два потока команд. В результате требуется множество соединений, чтобы данные могли перемещаться в нужных направлениях.
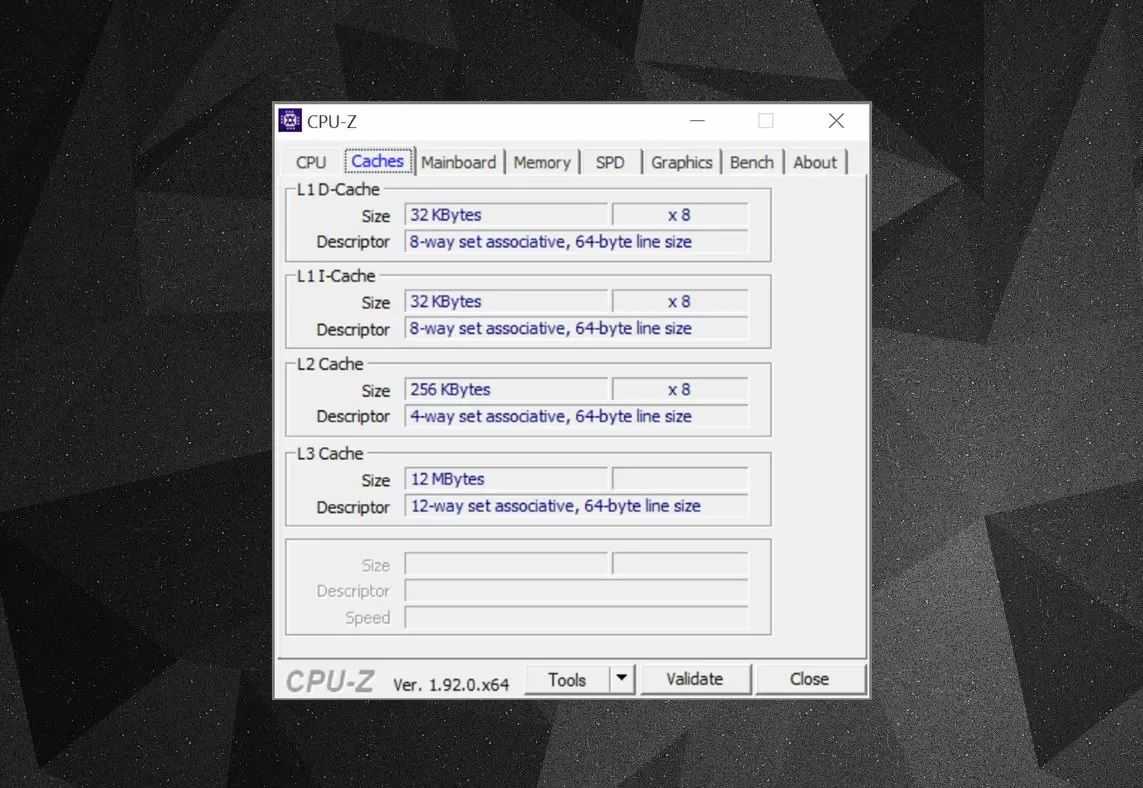
CPU-Z
Можно воспользоваться бесплатными программами вроде для просмотра информации о кэше процессора на вашем компьютере. Что означает эта информация? Важный элемент обозначается как модульно-ассоциативный. Это означает правила, по которым блоки данных из системной памяти копируются в кэш.
На изображении выше показана информация о кэше Intel Core i7-9700K. кэш первого уровня разделён на 64 небольших блока, которые называются наборы. Каждый из них разделён на линии кэша размером 64 байт. Модульно-ассоциативный означает, что блок данных из системной памяти помещается в линиях кэша одного определённого набора вместо того, чтобы помечаться где угодно.
Процессор Intel Core i7-9700K
8-канальный означает, что один блок может быть связан с восемью линиями кэша в наборе. Чем выше уровень ассоциативности, чем больше каналов, тем выше вероятность получить попадание в кэш, когда процессор ищет данные в нём. Это сокращает штраф в случае промаха в кэше.





Недостаток заключается в том, что это увеличивает сложность и энергопотребление, а также снижает производительность процессора. Ему приходится обрабатывать больше линий кэша для обработки блока данных.
Инклюзивный кэш L1+L2, кэш-жертва, политики обратной записи, ECC
Другой аспект сложности кэша относится к тому, как данные сохраняются на разных уровнях. Правила описываются в политике инклюзивности. Например, процессоры Intel Core обладают полностью инклюзивным кэшем L1+L3.
В некоторых процессорах кэш L2 не инклюзивный. Данные хранятся только на этом уровне кэша. Это экономит место, но системная память должна выполнять поиск в L3, который намного больше по размеру, чтобы найти нужный тег.
Кэш-жертва похож на предыдущий, но он используется для хранения информации, которая перемещается из кэша более низкого уровня. Например, процессоры на архитектуре AMD Zen 2 используют кэш-жертву L3, чтобы сохранять данные из L2.
Существуют и другие политики кэша. Например, когда данные записываются в кэш и основную системную память. Это называется политиками записи и большинство современных процессоров используют кэши с обратной записью (write-back).
Это означает, что когда данные записываются в кэше, есть задержка, прежде чем системная память получит обновлённую копию данных. По большей части эта пауза длится столько, сколько данные остаются в кэше. Когда они выгружаются, данные попадают в оперативную память.

Графический процессор Nvidia GA100 с кэшем L1 20 Мб и L2 40 Мб
Для разработчиков процессоров выбор количества, типа и политики кэшей представляет собой поиск баланса между производительностью, сложностью и размером чипа.
Если бы можно было обладать полностью ассоциативным 1000-канальным кэшем первого уровня объёмом 20 Мб без того, чтобы он был размером с целый квартал и с таким же расходом энергии, подобные процессоры уже были бы в компьютерах.
Кэши нижнего уровня в современных процессорах не менялись на протяжении последнего десятилетия. Зато постоянно растёт размер кэша L3. 10 лет назад в Intel i7-980X за $999 его размер составлял 12 Мб. Теперь в два раза дешевле можно взять процессор с кэшем 64 Мб.
Dzen News Google News
Уровни кэш-памяти ЦП: L1, L2 и L3
Кэш-память ЦП разделена на три «уровня»: L1, L2 и L3. Иерархия памяти снова соответствует скорости и, следовательно, размеру кеша.
Итак, влияет ли размер кеш-памяти процессора на производительность?
Кэш L1
Кэш L1 (уровень 1) – это самая быстрая память, которая присутствует в компьютерной системе. Что касается приоритета доступа, кэш L1 содержит данные, которые, скорее всего, потребуются ЦП при выполнении определенной задачи.
Не существует «стандартного» размера кеш-памяти L1, поэтому перед покупкой необходимо проверить спецификации ЦП, чтобы определить точный размер кеш-памяти L1.
Кэш L1 обычно делится на две части: кэш инструкций и кэш данных. Кэш инструкций имеет дело с информацией об операции, которую должен выполнить ЦП, в то время как кэш данных содержит данные, над которыми должна быть выполнена операция.
Кэш L2
Кэш L2 (уровень 2) медленнее, чем кеш L1, но больше по размеру. Если размер кэша L1 может измеряться в килобайтах, то в современных кэшах памяти L2 – в мегабайтах. Например, AMD Ryzen 5 5600X с высоким рейтингом имеет кэш L1 384 КБ и кэш L2 3 МБ (плюс кэш L3 32 МБ).
Размер кэша L2 зависит от ЦП, но обычно его размер составляет от 256 КБ до 8 МБ. Большинство современных процессоров имеют кэш L2 размером более 256 КБ, и этот размер сейчас считается небольшим. Кроме того, некоторые из самых мощных современных процессоров имеют больший объем кеш-памяти L2, превышающий 8 МБ.
Когда дело доходит до скорости, кэш L2 отстает от кеша L1, но по-прежнему намного быстрее, чем ваша системная RAM. Кэш памяти L1 обычно в 100 раз быстрее, чем ваша оперативная память, а кеш L2 примерно в 25 раз быстрее.
Кэш L3
В кэш L3 (уровень 3). Раньше кэш-память L3 фактически находилась на материнской плате. Это было очень давно, когда большинство процессоров были только одноядерными. Теперь кэш L3 в вашем процессоре может быть огромным, с топовыми потребительскими процессорами с кешами L3 до 32 МБ. Некоторые кэши L3 ЦП серверов могут превышать это значение, составляя до 64 МБ.
Кэш L3 – самый большой, но также самый медленный блок кэш-памяти. Современные процессоры включают кэш L3 на самом процессоре. Но в то время как кэш L1 и L2 существует для каждого ядра на самом чипе, кеш L3 больше похож на общий пул памяти, который может использовать весь чип.
На следующем изображении показаны уровни кэш-памяти ЦП для ЦП Intel Core i5-3570K:
Обратите внимание, как кэш L1 разделен на две части, а кеш L2 и L3 больше соответственно
Сколько мне нужно кэш-памяти ЦП?
Хороший вопрос. Как и следовало ожидать, чем больше, тем лучше. Последние процессоры, естественно, будут включать в себя больше кэш-памяти ЦП, чем предыдущие поколения, а также потенциально более быструю кеш-память. Вы можете научиться эффективно сравнивать процессоры . Существует много информации, и изучение того, как сравнивать и сравнивать разные процессоры, может помочь вам принять правильное решение о покупке.
Как узнать количество уровней и размер кэша на своем процессоре?
Начнем с того, что сделать это можно 3 способами:
- через командную строку (только кэш L2 и L3);
- путем поиска спецификаций в интернете;
- с помощью сторонних утилит.
Если взять за основу тот факт, что у большинства процессоров L1 составляет 32 КБ, а L2 и L3 могут колебаться в широких пределах, последние 2 значения нам и нужны. Для их поиска открываем командную строку через «Пуск» (вводим значение «cmd» через строку поиска).
Далее необходимо прописать значение «wmic cpu get L2CacheSize, L3CacheSize».
Система покажет подозрительно большое значение для L2. Необходимо поделить его на количество ядер процессора и узнать итоговый результат.







Если вы собрались искать данные в сети, то для начала узнайте точное имя ЦП. Нажмите правой кнопкой по иконке «Мой компьютер» и выберите пункт «Свойства». В графе «Система» будет пункт «Процессор», который нам, собственно, нужен. Переписываете его название в тот же Google или Yandex и смотрите значение на сайтах. Для достоверной информации лучше выбирать официальные порталы производителя (Intel или AMD). Третий способ также не вызывает проблем, но требует установки дополнительного софта вроде GPU-Z, AIDA64 и прочих утилит для изучения спецификаций камня. Вариант для любителей разгона и копошения в деталях.
Третий способ также не вызывает проблем, но требует установки дополнительного софта вроде GPU-Z, AIDA64 и прочих утилит для изучения спецификаций камня. Вариант для любителей разгона и копошения в деталях.
Техпроцесс в центральных и графических процессорах
Несмотря на то, что техпроцесс напрямую не влияет на производительность процессора, мы все равно будем упоминать его как характеристику процессора, так как именно техпроцесс влияет на увеличение производительности процессора, за счет конструктивных изменений. Хочу отметить, что техпроцесс, является общим понятием, как для центральных процессоров, так и для графических процессоров, которые используются в видеокартах.

Основным элементом в процессорах являются транзисторы – миллионы и миллиарды транзисторов. Из этого и вытекает принцип работы процессора. Транзистор, может, как пропускать, так и блокировать электрический ток, что дает возможность логическим схемам работать в двух состояниях – включения и выключения, то есть во всем хорошо известной двоичной системе (0 и 1).
Техпроцесс – это, по сути, размер транзисторов. А основа производительности процессора заключается именно в транзисторах. Соответственно, чем размер транзисторов меньше, тем их больше можно разместить на кристалле процессора.
Новые процессоры Intel выполнены по техпроцессу 22 нм. Нанометр (нм) – это 10 в -9 степени метра, что является одной миллиардной частью метра. Чтобы вы лучше смогли представить насколько это миниатюрные транзисторы, приведу один интересный научный факт: « На площади среза человеческого волоса, с помощью усилий современной техники, можно разместить 2000 транзисторных затворов!»
Если брать во внимание современные процессоры, то количество транзисторов, там уже давно перевалило за 1 млрд. Ну а техпроцесс у первых моделей начинался совсем не с нанометров, а с более объёмных величин, но в прошлое мы возвращаться не будем
Ну а техпроцесс у первых моделей начинался совсем не с нанометров, а с более объёмных величин, но в прошлое мы возвращаться не будем.
Примеры техпроцессов графических и центральных процессоров
Сейчас мы рассмотрим парочку последних техпроцессов, которые использовали известные производители графических и центральных процессоров.
1. AMD (процессоры):
Техпроцесс 32 нм. К таковым можно отнести Trinity, Bulldozer, Llano. К примеру, у процессоров Bulldozer, число транзисторов составляет 1,2 млрд., при площади кристалла 315 мм2.
Техпроцесс 45 нм. К таковым можно отнести процессоры Phenom и Athlon. Здесь примером будет Phemom, с числом транзисторов 904 млн. и площадью кристалла 346 мм2.
2. Intel:
Техпроцесс 22 нм. По 22-нм нормам построены процессоры Ivy Bridge (Intel Core ix — 3xxx). К примеру Core i7 – 3770K, имеет на борту 1,4 млрд. транзисторов, с площадью кристалла 160 мм2, видим значительный рост плотности размещения.

Техпроцесс 32 нм. К таковым можно отнести процессоры Intel Sandy Bridge (Intel Core ix – 2xxx). Здесь же, размещено 1,16 млрд. на площади 216 мм2.
Здесь четко можно увидеть, что по данному показателю, Intel явно обгоняет своего основного конкурента.
4. Nvidia:
Техпроцесс 28 нм. Geforce GTX 690

Вот мы и рассмотрели понятие техпроцесса в центральных и графических процессорах. На сегодняшний день разработчиками планируется покорить техпроцесс в 14 нм, а затем и 9, с применением других материалов и методов. И это далеко не предел!